高并发系统:系统可用性的度量
衡量指标
可用性是一个抽象的概念,你需要知道要如何来度量它,与之相关的概念是:MTBF 和 MTTR。
MTBF(Mean Time Between Failure) 是平均故障间隔的意思,代表两次故障的间隔时间,也就是系统正常运转的平均时间。这个时间越长,系统稳定性越高。
**MTTR(Mean Time To Repair)**表示故障的平均恢复时间,也可以理解为平均故障时间。这个值越小,故障对于用户的影响越小。
系统可用性指标:
Availability = MTBF / (MTBF + MTTR)
这个公式计算出的结果是一个比例,而这个比例代表着系统的可用性。一般来说,我们会使用几个九来描述系统的可用性。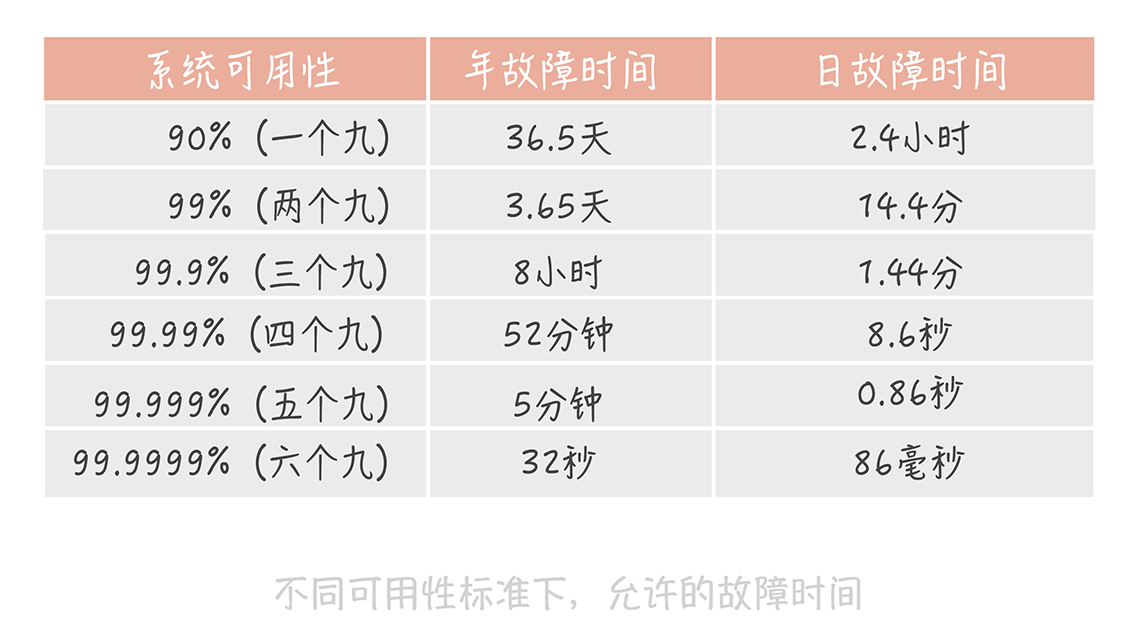
三个九之后,系统的年故障时间从 3 天锐减到 8 小时。
四个九之后,年故障时间缩减到 1 小时之内。在这个级别的可用性下,你可能需要建立完善的运维值班体系、故障处理流程和业务变更流程。你可能还需要在系统设计上有更多的考虑。比如,在开发中你要考虑,如果发生故障,是否不用人工介入就能自动恢复。当然了,在工具建设方面,你也需要多加完善,以便快速排查故障原因,让系统快速恢复。
五个九之后,故障就不能靠人力恢复了。想象一下,从故障发生到你接收报警,再到你打开电脑登录服务器处理问题,时间可能早就过了十分钟了。所以这个级别的可用性考察的是系统的容灾和自动恢复的能力,让机器来处理故障,才会让可用性指标提升一个档次。
设计思路
- 系统设计
- failover(故障转移)
心跳监测,故障转移 - 超时控制
通过收集系统之间的调用日志,统计比如说 99% 的响应时间是怎样的,然后依据这个时间来指定超时时间 - 降级
降级是为了保证核心服务的稳定而牺牲非核心服务的做法。 - 限流
通过对并发的请求进行限速来保护系统
- failover(故障转移)
- 系统运维
- 灰度发布
灰度发布指的是系统的变更不是一次性地推到线上的,而是按照一定比例逐步推进的。 - 故障演练
故障演练指的是对系统进行一些破坏性的手段,观察在出现局部故障时,整体的系统表现是怎样的,从而发现系统中存在的,潜在的可用性问题。
- 灰度发布