高并发系统:缓存使用-缓存穿透
在低缓存命中率的系统中,大量查询信息的请求会穿透缓存到数据库,因为数据库对于并发的承受能力是比较脆弱的。一旦数据库承受不了,查询就会变慢,大量的请求也会阻塞在数据库查询上,造成应用服务器的连接和线程资源被占满,最终导致你的电商系统崩溃。
一般来说,我们的核心缓存的命中率要保持在 99% 以上,非核心缓存的命中率也要尽量保证在 90%,如果低于这个标准你可能就需要优化缓存的使用方式了。
什么是缓存穿透
缓存穿透其实是指从缓存中没有查到数据,而不得不从后端系统(比如数据库)中查询的情况。
互联网系统的数据访问模型一般会遵从“80/20 原则”。大部分流量都在 20% 的热点数据上,而另外的 80% 的数据则不会被经常访问。理论上说,我们只需要在有限的缓存空间里存储 20% 的热点数据就可以有效地保护脆弱的后端系统了,也就可以放弃缓存另外 80% 的非热点数据了。所以这种少量的缓存穿透是不可避免的,但是对系统是没有损害的。
缓存穿透的解决方案
那如何解决缓存穿透呢?一般来说我们会有两种解决方案:回种空值以及使用布隆过滤器。
1、回种空值
当我们从数据库中查询到空值或者发生异常时,我们可以向缓存中回种一个空值。但是因为空值并不是准确的业务数据,并且会占用缓存的空间,所以我们会给这个空值加一个比较短的过期时间,让空值在短时间之内能够快速过期淘汰。下面是这个流程的伪代码:
1 | Object nullValue = new Object(); |
回种空值缺点:
虽然能够阻挡大量穿透的请求,但如果有大量不存在信息的查询请求,缓存内就会有有大量的空值缓存,也就会浪费缓存的存储空间,如果缓存空间被占满了,还会剔除掉一些已经被缓存的有效信息反而会造成缓存命中率的下降。所以这个方案,我建议你在使用的时候应该评估一下缓存容量是否能够支撑。
2、使用布隆过滤器
布隆过滤器说明
1970 年布隆提出了一种布隆过滤器的算法,用来判断一个元素是否在一个集合中。这种算法由一个二进制数组和一个 Hash 算法组成。
它的基本思路如下:
我们把集合中的每一个值按照提供的 Hash 算法算出对应的 Hash 值,然后将 Hash 值对数组长度取模后得到需要计入数组的索引值,并且将数组这个位置的值从 0 改成 1。在判断一个元素是否存在于这个集合中时,你只需要将这个元素按照相同的算法计算出索引值,如果这个位置的值为 1 就认为这个元素在集合中,否则则认为不在集合中。
下图是布隆过滤器示意图,我来带你分析一下图内的信息。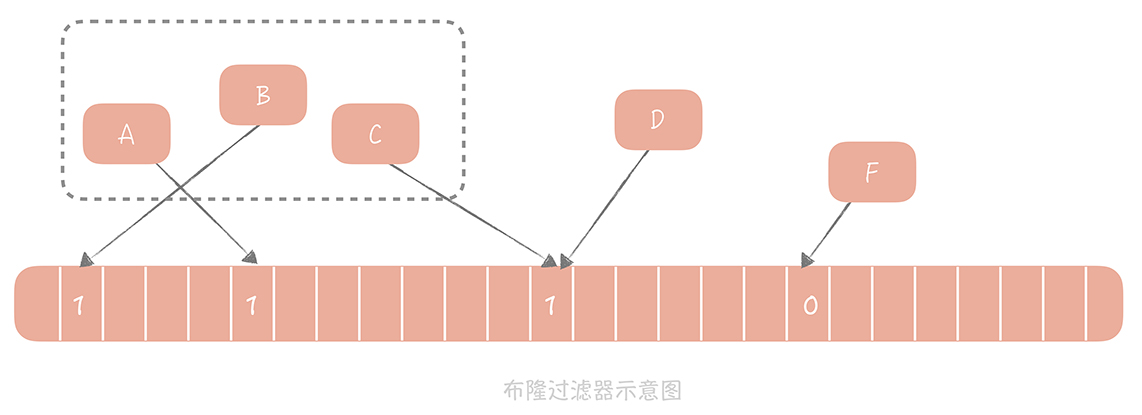
A、B、C 等元素组成了一个集合,元素 D 计算出的 Hash 值所对应的的数组中值是 1,所以可以认为 D 也在集合中。而 F 在数组中的值是 0,所以 F 不在数组中。
使用布隆过滤器来解决缓存穿透的问题
还是以存储用户信息的表为例进行讲解。首先我们初始化一个很大的数组,比方说长度为 20 亿的数组,接下来我们选择一个 Hash 算法,然后我们将目前现有的所有用户的 ID 计算出 Hash 值并且映射到这个大数组中,映射位置的值设置为 1,其它值设置为 0。
新注册的用户除了需要写入到数据库中之外,它也需要依照同样的算法更新布隆过滤器的数组中相应位置的值。那么当我们需要查询某一个用户的信息时,先查询这个 ID 在布隆过滤器中是否存在,如果不存在就直接返回空值,而不需要继续查询数据库和缓存,这样就可以极大地减少异常查询带来的缓存穿透。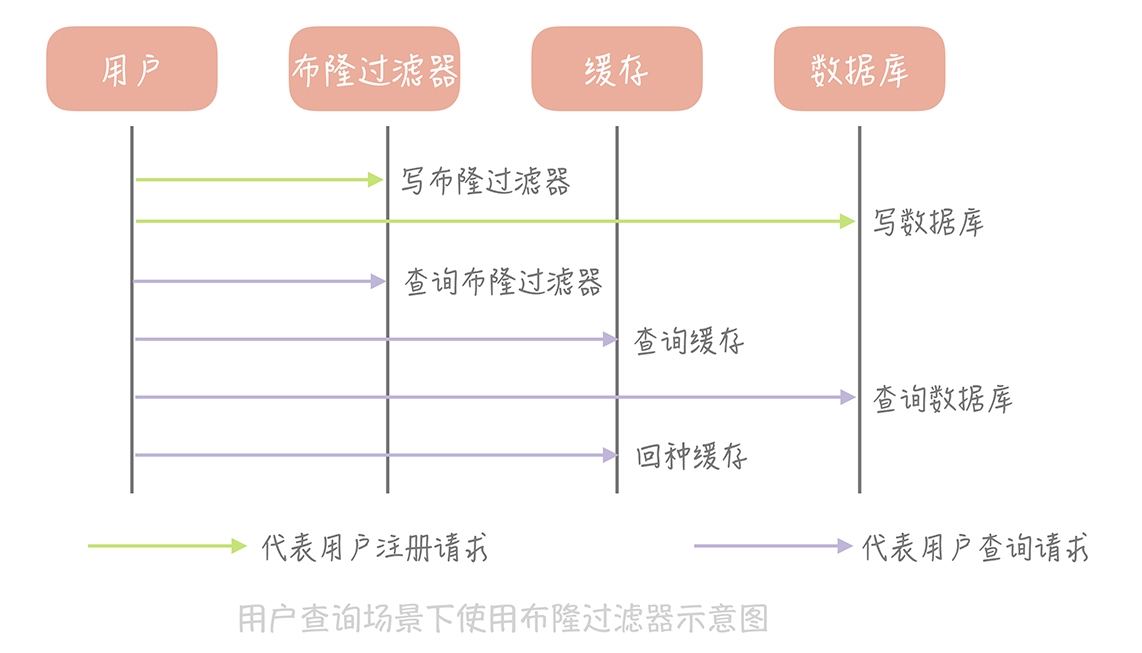
布隆过滤器拥有极高的性能,无论是写入操作还是读取操作,时间复杂度都是 O(1) 是常量值。在空间上,相对于其他数据结构它也有很大的优势,比如,20 亿的数组需要 2000000000/8/1024/1024 = 238M 的空间,而如果使用数组来存储,假设每个用户 ID 占用 4 个字节的空间,那么存储 20 亿用户需要 2000000000 * 4 / 1024 / 1024 = 7600M 的空间,是布隆过滤器的 32 倍。
布隆过滤器缺陷
1. 它在判断元素是否在集合中时是有一定错误几率的,比如它会把不是集合中的元素判断为处在集合中:
主要是 Hash 算法的问题,Hash 算法存在着一定的碰撞几率。但因为布隆过滤器的特点恰巧非常适合解决缓存穿透的问题。因为当布隆过滤器判断元素在集合中时,这个元素可能不在集合中。但是一旦布隆过滤器判断这个元素不在集合中时,它一定不在集合中。
当然如果在乎碰撞率问题,**解决方案是:**使用多个 Hash 算法为元素计算出多个 Hash 值,只有所有 Hash 值对应的数组中的值都为 1 时,才会认为这个元素在集合中。
2. 不支持删除元素。
布隆过滤器不支持删除元素的缺陷也和 Hash 碰撞有关。
假如两个元素 A 和 B 都是集合中的元素,它们有相同的 Hash 值,它们就会映射到数组的同一个位置。这时我们删除了 A,数组中对应位置的值也从 1 变成 0,那么在判断 B 的时候发现值是 0,也会判断 B 是不在集合中的元素,就会得到错误的结论。
解决方案是:
将标志位0,1修改为计数方式。缺点是增加空间消耗。
所以,你要依据业务场景来选择是否能够使用布隆过滤器
总的来说,回种空值和布隆过滤器是解决缓存穿透问题的两种最主要的解决方案,但是它们也有各自的适用场景,并不能解决所有问题。
dog-pile effect(狗桩效应)
当有一个极热点的缓存项,它一旦失效会有大量请求穿透到数据库,这会对数据库造成瞬时极大的压力,我们把这个场景叫做“dog-pile effect”(狗桩效应),
解决方案:
- 在代码中控制在某一个热点缓存项失效之后启动一个后台线程,穿透到数据库,将数据加载到缓存中,在缓存未加载之前,所有访问这个缓存的请求都不再穿透而直接返回。
- 通过在 Memcached 或者 Redis 中设置分布式锁,只有获取到锁的请求才能够穿透到数据库。
综上
- 回种空值是一种最常见的解决思路,实现起来也最简单,如果评估空值缓存占据的缓存空间可以接受,那么可以优先使用这种方案;
- 布隆过滤器会引入一个新的组件,也会引入一些开发上的复杂度和运维上的成本。所以只有在存在海量查询数据库中,不存在数据的请求时才会使用,在使用时也要关注布隆过滤器对内存空间的消耗;
- 对于极热点缓存数据穿透造成的“狗桩效应”,可以通过设置分布式锁或者后台线程定时加载的方式来解决。