高并发系统:缓存简介
什么是缓存
缓存,是一种存储数据的组件,它的作用是让对数据的请求更快地返回。凡是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为缓存。
常见硬件组件的延时情况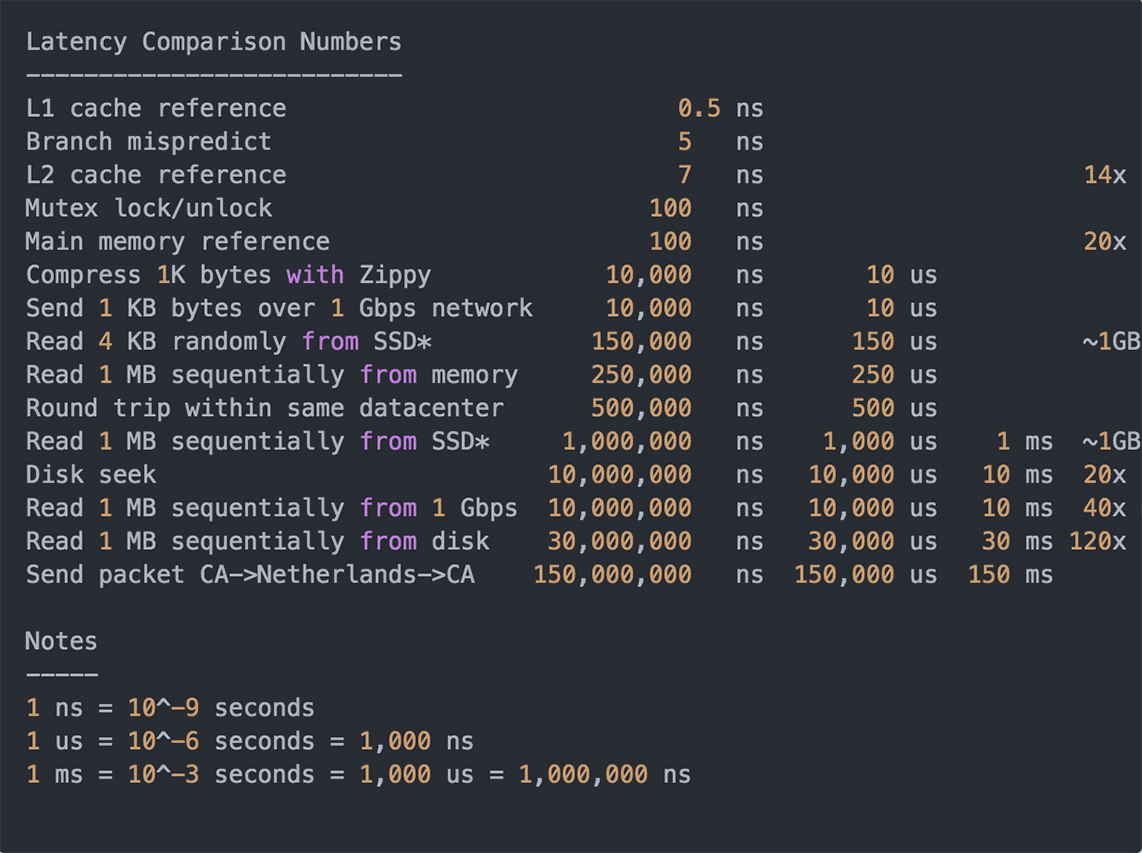
从这些数据中,你可以看到,做一次内存寻址大概需要 100ns,而做一次磁盘的查找则需要 10ms。如果我们将做一次内存寻址的时间类比为一个课间,那么做一次磁盘查找相当于度过了大学的一个学期。可见,我们使用内存作为缓存的存储介质相比于以磁盘作为主要存储介质的数据库来说,性能上会提高多个数量级,同时也能够支撑更高的并发量。所以,内存是最常见的一种缓存数据的介质。
缓存分类
在我们日常开发中,常见的缓存主要就是分布式缓存、热点本地缓存、静态缓存这几种。
分布式缓存
分布式缓存的大名可谓是如雷贯耳了,我们平时耳熟能详的 Memcached、Redis 就是分布式缓存的典型例子。它们性能强劲,通过一些分布式的方案组成集群可以突破单机的限制。所以在整体架构中,分布式缓存承担着非常重要的角色,后边细谈。
热点本地缓存
当我们遇到极端的热点数据查询的时候。热点本地缓存主要部署在应用服务器的代码中,用于阻挡热点查询对于分布式缓存节点或者数据库的压力。如 HashMap,Guava Cache 或者是 Ehcache 等,它们和应用程序部署在同一个进程中,优势是不需要跨网络调度,速度极快,所以可以用来阻挡短时间内的热点查询。
Guava 的 Loading Cache代码样例:
1 | CacheBuilder<String, List<Product>> cacheBuilder = CacheBuilder.newBuilder().maximumSize(maxSize).recordStats(); //设置缓存最大值 |
由于本地缓存是部署在应用服务器中,而我们应用服务器通常会部署多台,当数据更新时,我们不能确定哪台服务器本地中了缓存,更新或者删除所有服务器的缓存不是一个好的选择,所以我们通常会等待缓存过期。因此,这种缓存的有效期很短,通常为分钟或者秒级别,以避免返回前端脏数据。
静态缓存
如CDN等,后续单独整理。
缓存的不足
- **首先,缓存比较适合于读多写少的业务场景,并且数据最好带有一定的热点属性。**这是因为缓存毕竟会受限于存储介质不可能缓存所有数据,那么当数据有热点属性的时候才能保证一定的缓存命中率
- **其次,缓存会给整体系统带来复杂度,并且会有数据不一致的风险。**当更新数据库成功,更新缓存失败的场景下,缓存中就会存在脏数据。对于这种场景,我们可以考虑使用较短的过期时间或者手动清理的方式来解决。
- **再次,之前提到缓存通常使用内存作为存储介质,但是内存并不是无限的。**因此,我们在使用缓存的时候要做数据存储量级的评估,对于可预见的需要消耗极大存储成本的数据,要慎用缓存方案。同时,缓存一定要设置过期时间,这样可以保证缓存中的会是热点数据。
- **最后,缓存会给运维也带来一定的成本。**运维需要对缓存组件有一定的了解,在排查问题的时候也多了一个组件需要考虑在内。
1 | 虽然有这么多的不足,但是缓存对于性能的提升是毋庸置疑的,我们在做架构设计的时候也需要把它考虑在内,只是在做具体方案的时候需要对缓存的设计有更细致的思考,才能最大化地发挥缓存的优势。 |
注意问题
- 缓存可以有多层,比如上面提到的静态缓存处在负载均衡层,分布式缓存处在应用层和数据库层之间,本地缓存处在应用层。我们需要将请求尽量挡在上层,因为越往下层,对于并发的承受能力越差;
- 缓存命中率是我们对于缓存最重要的一个监控项,越是热点的数据,缓存的命中率就越高
当在实际工作中碰到“慢”的问题时,缓存就是你第一时间需要考虑的。